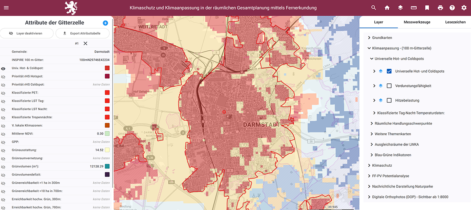
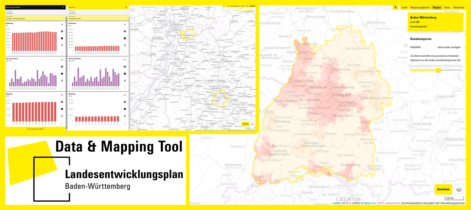
WebGIS for Climate Protection and Adaptation in Hesse, Germany
Climate change adaptation is one of the main challenges in spatial planning. Priority areas for climate protection need to be identified in order for robust and sustainable measures to be implemented. Such analysis relies on a tremendous amount of data. To reduce the planning workload in the German state…
Read More